Jager and Leek 2014 (PubMed/Medline)
To download only this data file: JagerLeek.rds (331 KB)
To download all BEAR datasets, click here.
Jager and Leek 2014 (PubMed/Medline)
Reference: Jager and Leek (2014).
Research question: estimating science-wise false discovery rate.
Data collection: authors used a custom program to extract p-values from scraped PubMed abstracts for papers published in 5 main medical journals 2000-2010. 15,653 p-values are available in 5,322 articles.
Data availability: the data file pvalueData.rda is available https://github.com/jtleek/swfdr License for the programs in that repository is GNU GPL, although a license for the dataset is not stated, as far as we are aware.
Data processing: there was only minimal processing. We derived unsigned z values from p-values assuming they were two-sided.
Notably, large proportion of p-values is truncated, almost always at 0.0001, 0.001, 0.01, or 0.05. As in all datasets, we retained information on truncation. We also treated p-values recorded as exactly 0 as truncated (z-operator >). We created a crude flag for RCTs by searching the paper titles for “randomized”, “randomised” and “controlled”.
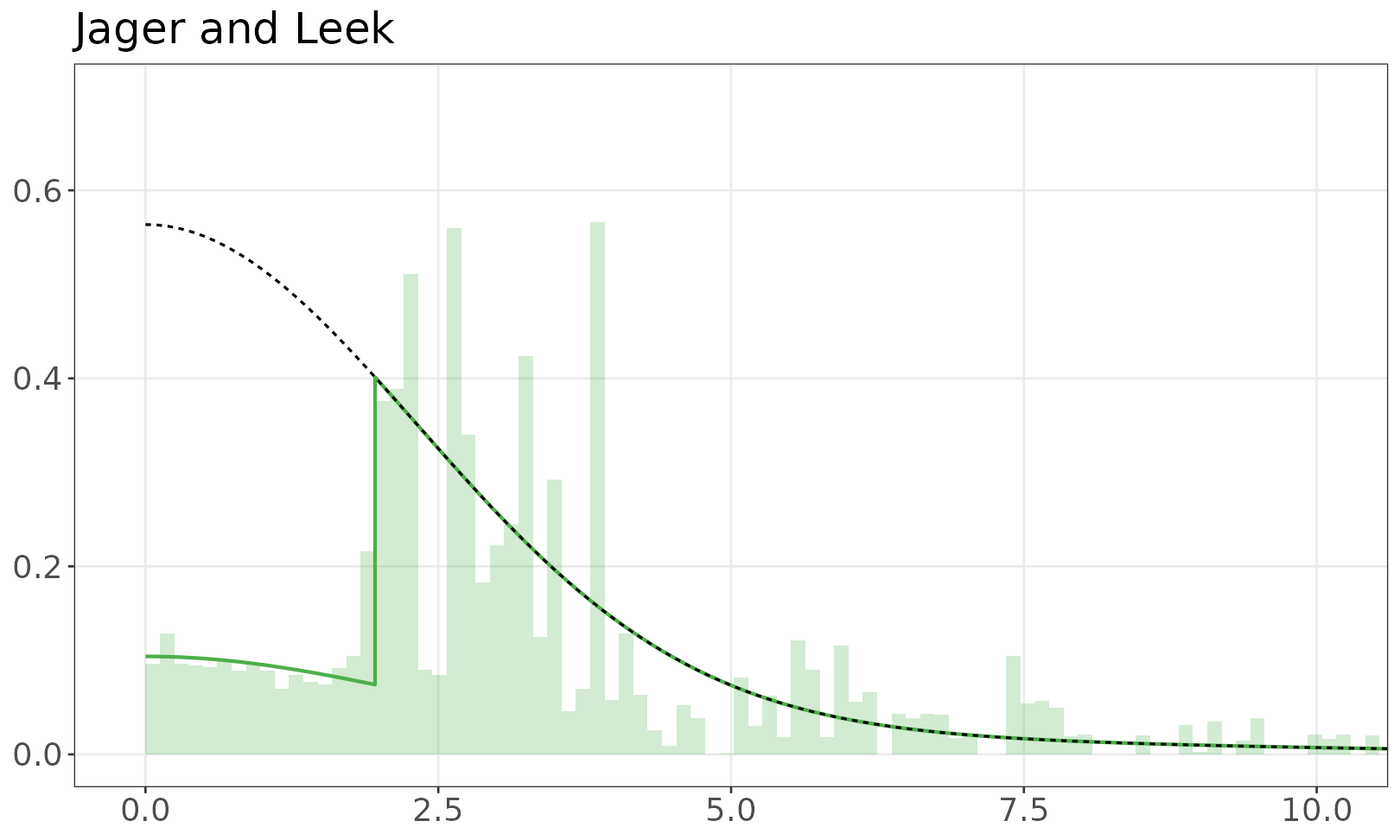
Model of z-values
The fitted mixture model is shown over the empirical distribution of absolute z-values. The solid line is a mixture of half-normals, with selection. The dashed line shows the distribution without selection. If there are inequalities (e.g. studies reporting p < 0.05) the histogram resamples values from the appropriate set.