Head et al 2015 (PubMed/Medline)
Head et al 2015 (PubMed/Medline)
Reference: Head et al. (2015).
Research question: extent of p-hacking and its impact on meta-analyses.
Data collection: PubMed papers that are open access, up to 2014. Authors used regular expressions to extract p-values from text of Abstract and Results, but not tables. Downloaded data has about 220,000 studies and about 2mln rows.
Data availability: dataset available at https://datadryad.org/dataset/doi:10.5061/dryad.79d43 under CC0 1.0 Universal licence.
Data processing: we followed the same minimal clean-up steps (e.g. removing values found in large supplementary sections) as the original paper and also attached PubMed IDs to the dataset using DOI look-up.
When constructing the BEAR dataset, we derived unsigned z-values from p-values. We treated p-values recorded as exactly 0 as truncated and set the z-operator to >. We recoded all inequalities to sharp inequalities. For the distributed version of BEAR 50,000 studies are selected at random, with one row per study, in order to keep the file size manageable.
Additional variables used: we use the “Abstract vs Results” variable for grouping
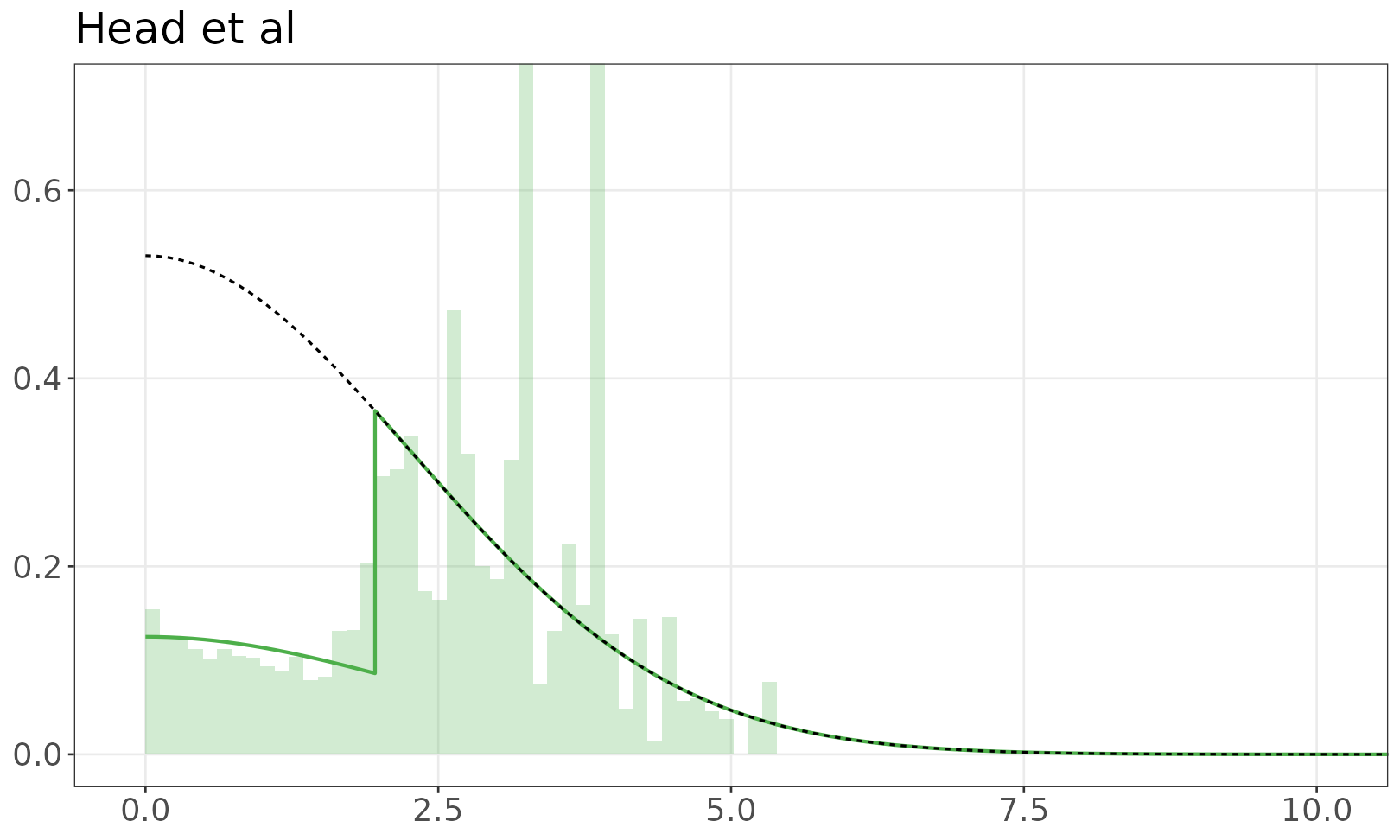
Model of z-values
The fitted mixture model is shown over the empirical distribution of absolute z-values. The solid line is a mixture of half-normals, with selection. The dashed line shows the distribution without selection. If there are inequalities (e.g. studies reporting p < 0.05) the histogram resamples values from the appropriate set.